基础知识

基本概念
外键
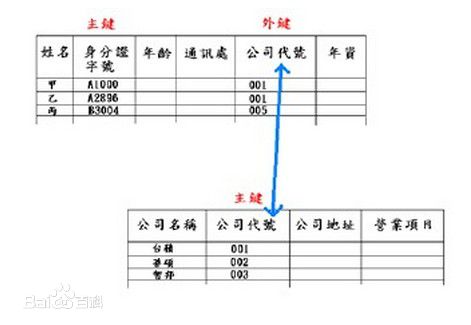
主键
主关键字(primary key)是表中的一个或多个字段,它的值用于唯一地标识表中的某一条记录。在两个表的关系中,主关键字用来在一个表中引用来自于另一个表中的特定记录。主关键字是一种唯一关键字,表定义的一部分。一个表的主键可以由多个关键字共同组成,并且主关键字的列不能包含空值。主关键字是可选的,并且可在 CREATE TABLE 或 ALTER TABLE 语句中定义。
在设计数据库时,选择其中一个候选键作为主键。 使用此术语是因为此键将定义到DBMS,DBMS将使用它作为查找表中行的主要方法。表只有一个主键。 主键可以有一列,也可以是复合列。
候选码
若关系中的一个属性或属性组的值能够唯一地标识一个元组,且他的真子集不能唯一的标识一个元组,则称这个属性或属性组做候选码。
候选键是决定关系中所有其他列的决定因素。 SKU_DATA 表中有两个候选键:SKU和SKU_Description。买方是一个决定因素,但它不是候选关键,因为它只决定部门。 ORDER_ITEM 表只有一个候选键:( OrderNumber,SKU)。此表中的另一个决定因素(数量,价格)不是候选键,因为它仅确定 ExtendedPrice。
超键
超键(英语:superkey),有的文献称“超码”,是在数据库关系模式设计中能够唯一标示多元组(即“行”)的属性集。
代理键
代理键是一个人工列,它被添加到表中以作为主键。创建行时,DBMS会为代理键分配唯一值。指定的值永远不会改变。当主键很大且不实用时使用代理键。例如,考虑RENTAL_PROPERTY的关系:
RENTAL_PROPERTY(街道,城市,州/省,邮政编码,国家,Rental_Rate)
该表的主键是(Street,City,State / Province,Zip / PostalCode,Country)。正如您将在第6章中学到的,为了获得良好的性能,主键应该很短,如果可能的话,应该是数字键。 RENTAL_PROPERTY的主键都不是。在这种情况下,数据库的设计者可能会创建一个代理键。该表的结构将是:RENTAL_PROPERTY(PropertyID,街道,城市,州/省,邮编/邮政编码,国家,Rental_Rate) 创建行时,DBMS将为PropertyID分配数值。使用该密钥将比使用原始密钥产生更好的性能。请注意,代理键值是人为的,对用户没有任何意义。事实上,代理键值通常隐藏在表单和报表中。
数据模型
理解:数据模型是对现实世界的模拟。
数据模型是用来 描述数据、组织数据、操作数据的。
数据模型分为两个层次,现实世界的客观对象抽象成概念模型,然后再转换成机器模型。
- 概念模型 按照用户观点对数据建模,主要用于数据库设计,
- 机器模型 分为逻辑模型和物理模型。逻辑模型主要包括层次模型(树)、网状模型(图)、关系模型等,它是按计算机系统的观点对数据建模。 物理模型是机器内部的存储方式和存取方法,由DBMS实现。
组成要素: 数据结构、数据操作、数据的完整性约束条件
经典的表
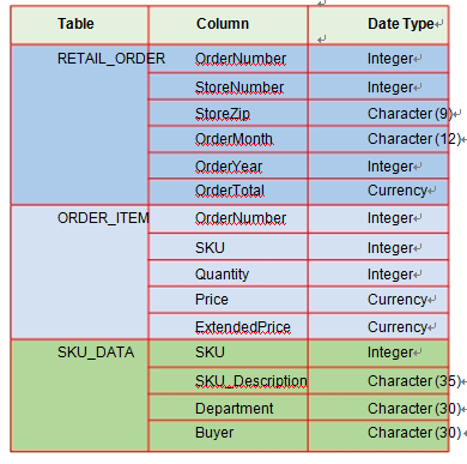
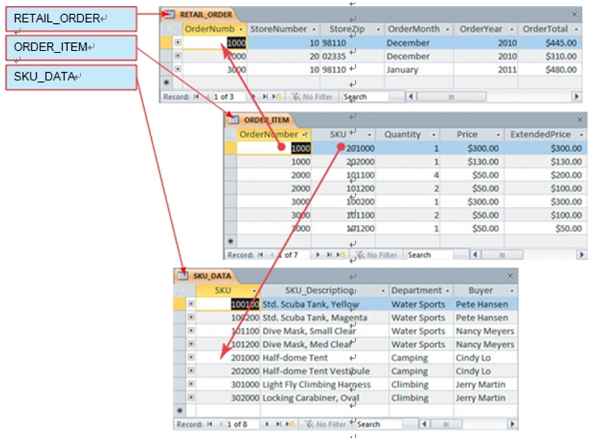
- Retail_order: 订单
- Order_item: 订单中的物品
- Sku_data: 最小库存单元
SQL
模式
select–from–where–group by–having–order by
ORDER BY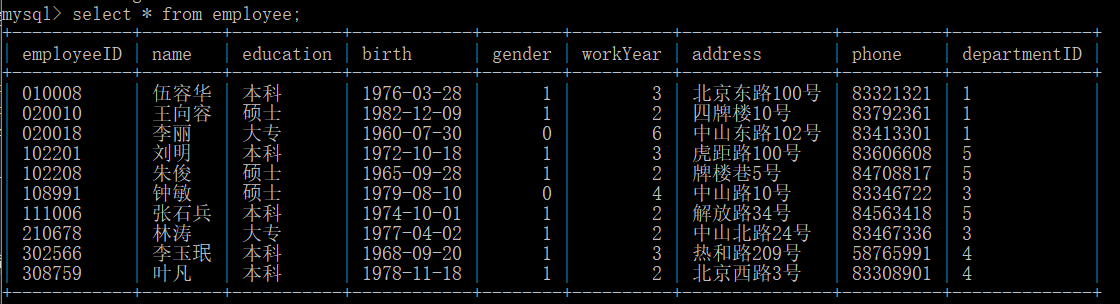
第一个先排序,第一个无法确定再看第二个参数,DESC 代表从大到小排序。相应的, ASC 代表从小到大的排序,默认从小到大。1
SELECT gender ,employeeID from employee ORDER BY gender ,employeeID DESC;
IN1
2
3SELECT *
FROM SKU_DATA
WHERE Buyer IN ('Nancy Meyers', 'Cindy Lo', 'Jerry Martin');
1 | SELECT * |
BETWEEN
不同的数据库对 BETWEEN…AND 操作符的处理方式是有差异的。
1 | SELECT * |
LIKE
查询包含Tent的单词1
2
3SELECT *
FROM SKU_DATA
WHERE Buyer LIKE '%Tent%';
_ 下划线仅替代一个字符,通配符

1 | SELECT * |
SQL Built-in Functions 1
2
3
4
5SELECT SUM(ExtendedPrice) AS OrderItemSum,
AVG(ExtendedPrice) AS OrderItemAvg,
MIN(ExtendedPrice) AS OrderItemMin,
MAX(ExtendedPrice) AS OrderItemMax
FROM ORDER_ITEM;
1 | SELECT COUNT(DISTINCT Department) AS DeptCount |
这样做是错误的,除了 GROUP BY 之外,不能将表列名称与SQL内置函数组合在一起1
2SELECT department,COUNT(*)
FROM SKU_data;
1 | SELECT * |
乘法1
2SELECT Quantity * Price AS EP
FROM ORDER_ITEM;
字符串连接
这种方式不漂亮1
2SELECT Buyer+' in '+Department AS Sponsor
FROM SKU_DATA;
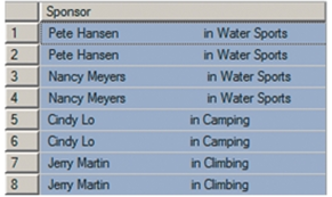
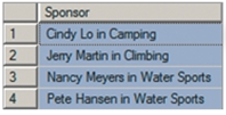
利用 RTRIM1
2SELECT DISTINCT RTRIM(Buyer)+' in '+RTRIM(Department) AS Sponsor
FROM SKU_DATA;
GROUP BY1
2
3SELECT Department, COUNT(*) AS Dept_SKU_Count
FROM SKU_DATA
GROUP BY Department;
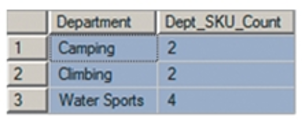
内置函数可以用在 having 子句中
子查询1
2
3
4
5
6
7
8
9
10
11
12SELECT Buyer, COUNT(*) AS NumberSold
FROM SKU_DATA
WHERE SKU IN
(SELECT SKU
FROM ORDER_ITEM
WHERE OrderNumber IN
(SELECT OrderNumber
FROM RETAIL_ORDER
WHERE OrderMonth='January'
AND OrderYear=2011))
GROUP BY Buyer
ORDER BY NumberSold DESC;
连接查询
内链接,三种方式实现,只有在连接的表内数据都存在的情况下,才会做连接。内连接是把二个表连接成一个结果集,在这个结果集中仅包含那些满足条件的记录行。1
2
3
4SELECT MAX(salary.income),MIN(salary.income)
FROM salary,employee //FROM 两张表
WHERE employee.departmentID = 1
AND employee.employeeID = salary.employeeID; <----
1 | SELECT departName |
1 | SELECT departName |
外连接
如果存在不能匹配的数据,也会进行连接,不过此时 mysql 会帮我们虚拟一条不存在的记录,字段值都是为 null,帮我们完成整个连接记录。
分为左外连接和右外连接:1
2左外连接 : left join on, left outer join on;
右外连接 :right join on, right outer join on;
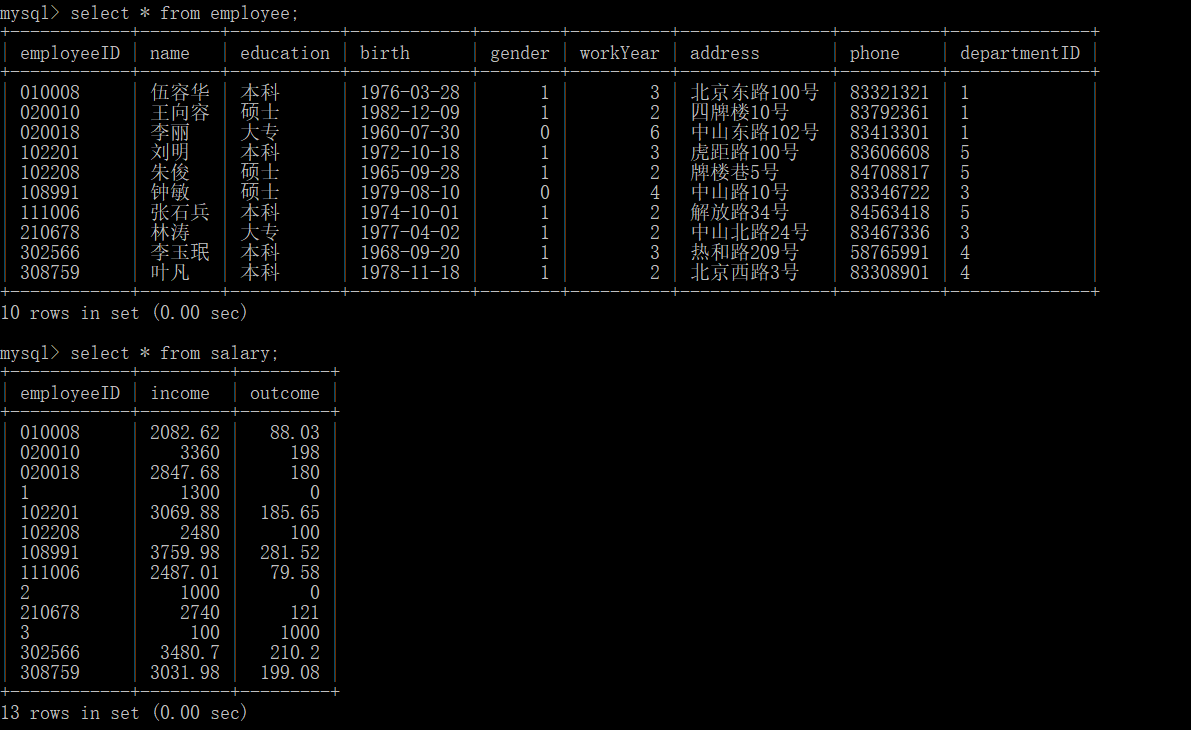
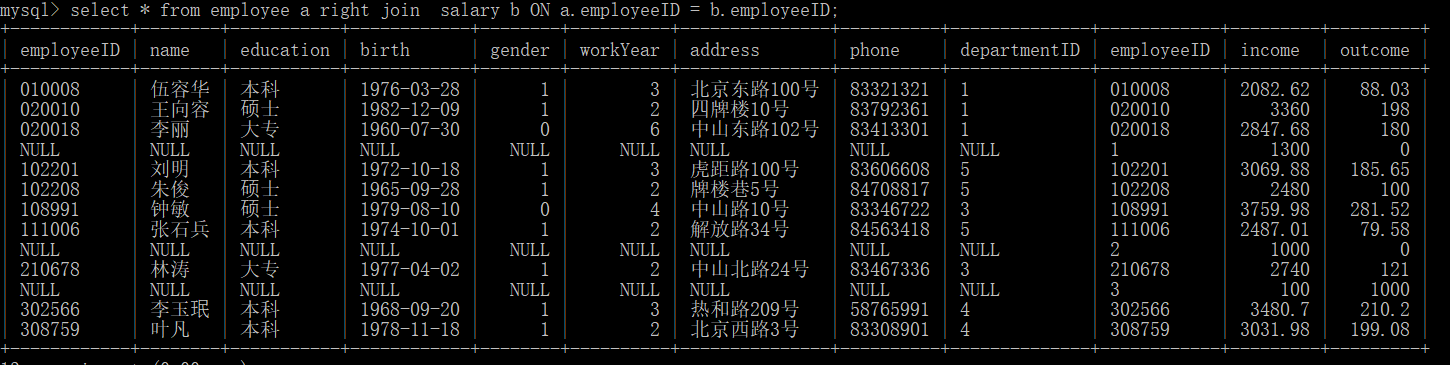
salary表中比employee表多了几行数据,经过右外连接,缺少的字段用 null 代替了。
函数依赖
函数依赖简单点说就是:某个属性集决定另一个属性集时,称另一属性集依赖于该属性集。
函数依赖是由数学派生的术语,它表征一个属性或属性集合的值对另一个属性或属性集合的值的依赖性。需要强调的是,函数依赖是关系所表述信息本身具有的语义特性,而不能由属性构成关系的方式来决定,也不能由关系的当前内容所决定。
函数依赖是数据库设计过程的核心,需要好好理解
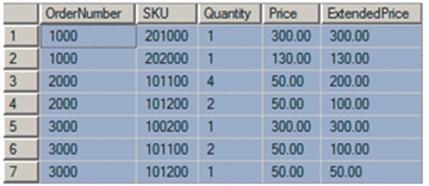
函数依赖为:
- SKU → Price
- (OrderNumber, SKU) →Price
- (OrderNumber, SKU) →(Quantity, Price, ExtendedPrice)
- (Quantity, Price) →ExtendedPrice
- 考虑 OrderNumver ,发现一个 OrderNumber 可以对应多个 SKU,Quantity,ExtendedPrice,不存在决定关系。
- 考虑 SKU,发现一个 SKU (101100)可以对应多个OrderNumber, 和多个Quantity,但是只有一个 Price,得出一个函数依赖关系。SKU → Price
- 考虑 两者联合 ,发现可以确定所有的字段
- 考虑 Quantity 和 Price ,可以得到(Quantity, Price) →ExtendedPrice,因为 Quantity * Price = ExtenedPrice
范式
分类
BCNF,1NF, 2NF, 3NF, 4NF
1NF
是数据库正规化中所使用的一种正规形式。第一正规化是为了要排除 重复群 的出现,所采用的方法是要求数据库的每个列的值域都是由原子值组成;每个字段的值都只能是单一值。
具有删除异常,修改异常,插入异常。
2NF
是数据库正规化中所使用的一种正规形式。它的规则是要求数据表里的所有数据都要和该数据表的键(主键与候选键)有完全依赖关系:每个非键属性必须独立于任意一个候选键的任意一部分属性。如果有哪些数据只和一个键的一部分有关的话,就得把它们独立出来变成另一个数据表。如果一个数据表的键只有单个字段的话,它就一定匹配第二范式。
理解:每一个非候选码键的字段依赖于候选键。
一个数据表匹配第二范式当且仅当
- 它匹配第一正规化
- 所有非键的字段都一定是候选键全体字段的函数
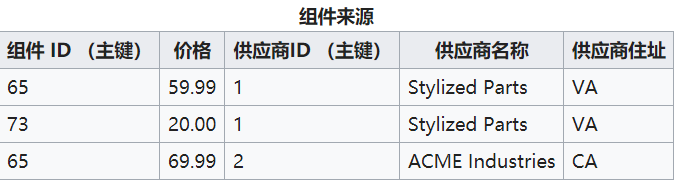
将上表变为下面两张表,因为供应商名称和供应商地址只与供应商ID 有关
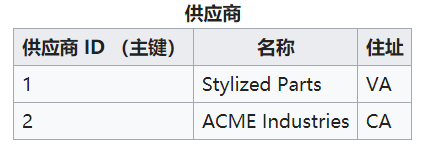
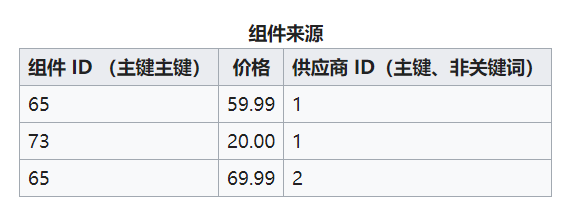
3NF
要求所有非键属性都只和候选键有相关性,也就是说非键属性之间应该是独立无关的。

所有非主键字段依赖于主键,满足第二范式,但是小计依赖于单价和数量,第三范式需要非主键字段之间不能有关系,所以不满足第三范式,可以直接将小计去掉,即满足第三范式。
BCNF
是数据库规范化的一种正规形式。是在第三范式的基础上加上稍微更严格约束,每个 BCNF 关系都满足第三范式。BCNF 去除了属性间的不必要的函数依赖。
BCNF的定义是:如果对于关系模式R中存在的任意一个非平凡函数依赖X->A,都满足X是R的一个超键,那么关系模式R就属于BCNF。
对上述定义,可以理解为:平凡函数依赖关系是指,如果属性集合X包含了属性集合A,那么就一定有X->A;超键是指能够唯一确定表中各行的属性集合,因此一个超键的最小化就是一个候选键;BCNF是说,如果一个属性集合X能“不平凡”地推导出另一个属性集合A,而且X还不能唯一区分表的各行,那么这个表中一定包含了一些冗余信息。
BCNF与第三范式的不同之处在于:第三范式中不允许非主属性被另一个非主属性决定,但第三范式允许主属性被非主属性决定;而在BCNF中,任何属性(包括非主属性和主属性)都不能被非主属性所决定。
任何一个BCNF必然满足:
- 所有非主属性都完全函数依赖于每个候选键
- 所有主属性都完全函数依赖于每个不包含它的候选键
- 没有任何属性完全函数依赖于非候选键的任何一组属性
4NF
定义:数据库的一个表遵从第四范式,当且仅当对于任意一个非平凡的多值依赖X ->-> Y, X是一个超键。
理解:在 BC 范式的基础上消除多值依赖。如果存在一对多,这个一肯定不是超键,也就是说不是第四范式。
多值依赖
If the column headings in a relational database table are divided into three disjoint groupings X, Y, and Z, then, in the context of a particular row, we can refer to the data beneath each group of headings as x, y, and z respectively. A multivalued dependency X ->-> Y signifies that if we choose any x actually occurring in the table (call this choice xc), and compile a list of all the XcYZ combinations that occur in the table, we will find that Xc is associated with the same y entries regardless of z. So essentially the presence of z provides no useful information to constrain the possible values of y.
多值依赖属4nf的定义范围,比函数依赖要复杂得多。在关系模式中,函数依赖不能表示属性值之间的一对多联系,这些属性之间有些虽然没有直接关系,但存在间接的关系,把没有直接联系、但有间接的联系称为多值依赖的数据依赖。
在函数依赖中,X与Y是否存在函数依赖关系,只需考察X,Y的两组属性,与别的属性无关。而在多值依赖中,X与Y是否存在多值依赖还需看属性Z。